
Developing data processing AI agents: a letter from the development team

In our previous article, we went behind-the-scenes of our “no-code to low-code” update in Morph Beta2. The other big update for Beta2 was significantly overhauling AI functionality.
One of the key areas of focus was developing AI agents, which has been attracting a lot of attention in the LLM world recently.
From No-Code to Low-Code: Letter from the Development Team
What is an AI agent?
Before talking about the AI agents we are working on at Morph, let me first briefly explain what an AI agent is.
An AI agent is a software program that performs task planning, data collection, task execution, and evaluation of execution results in order to achieve a goal given by the user, and executes the task autonomously.
Representative AI agents include BabyAGI, which was announced as an OSS project in May 2023, and Devin, which has attracted attention as an AI software engineer.
AI agents have the potential to handle complex tasks that cannot be performed by LLMs alone.
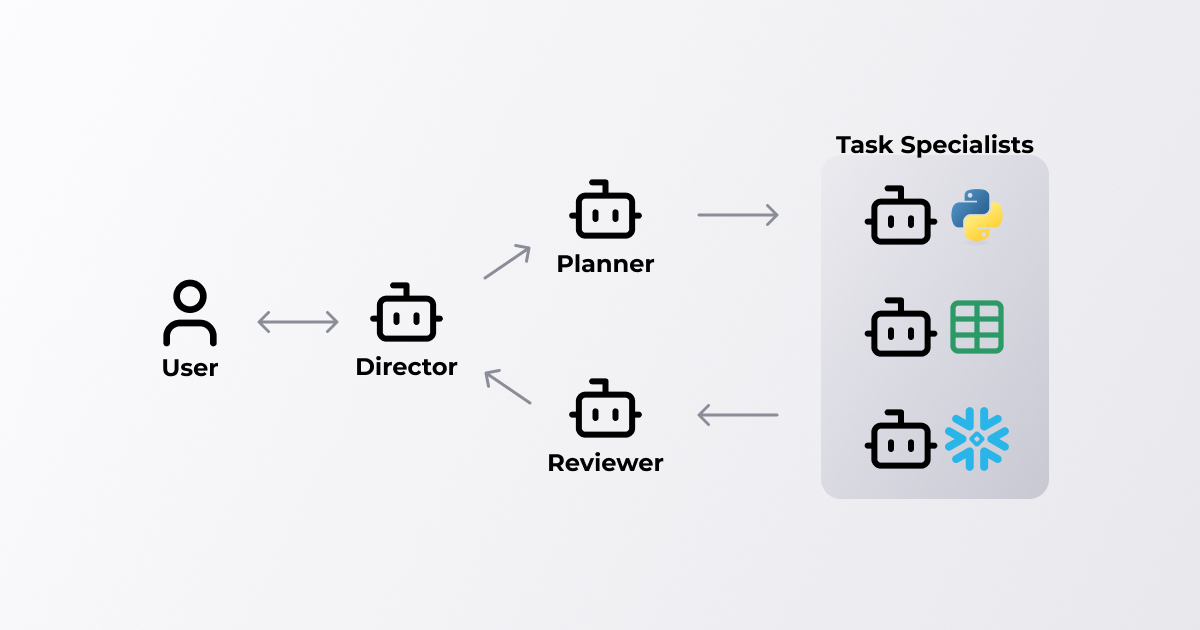
Morph is developing an AI agent specialized for data processing
Morph is developing AI agents specialized for data processing, utilizing LLM's coding, explanation, and data interpretation capabilities. By having a LLM generate this code, we are aiming to create an agent that can perform all kinds of data processing tasks.
As shown in the figure below, Morph's AI agents are composed of multiple agents that specialize in a single task and cooperate with each other to perform data processing. By working together, the system as a whole is able to behave autonomously.
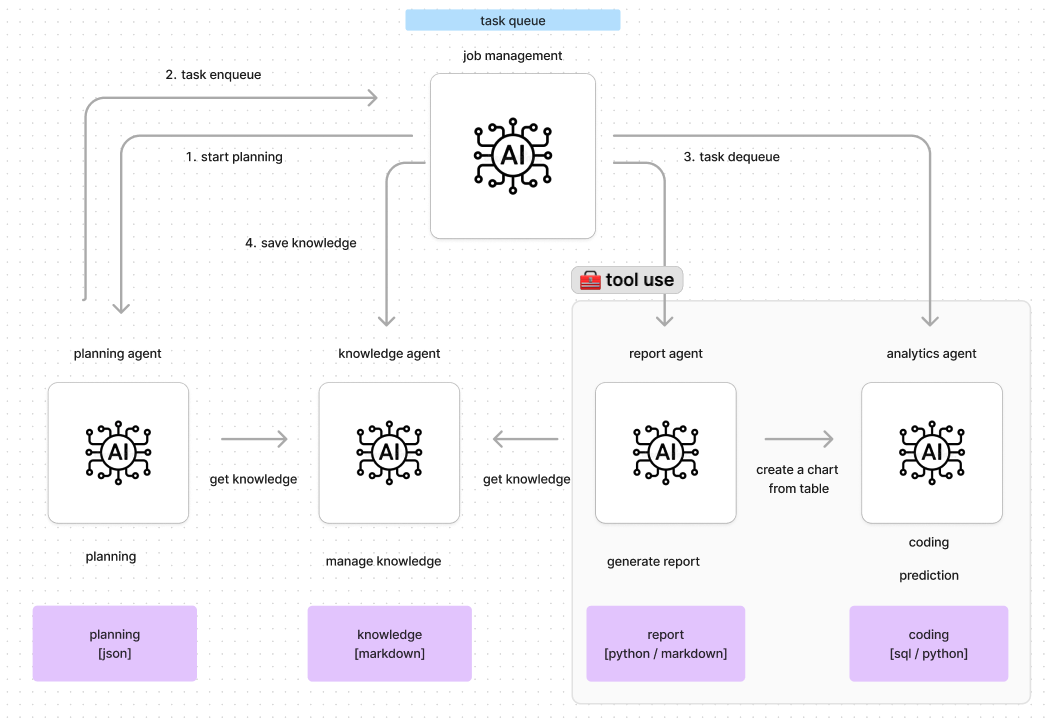
Code generation by AI continues to improve dramatically. Therefore, if the data structure to be analyzed is properly detailed to the AI, correct code can be obtained directly with a fairly high probability.
On our journey of developing the AI agents, we found that task inference capability plays the most important role.
When users request data analysis process, the AI agents generates a list of tasks based on the following knowledge:
- Detailed information on available data
AI agents verify that all data is available to perform the requested process. If any information is missing, the AI agent will ask the user for additional information.
- Tools the AI agents can use [Python, SQL]
AI agents can utilize available Python packages and SQL syntax. It also manages the dependencies of the processes so that they are executed as a pipeline.
- Knowledge given by the user
We have an agent that manages knowledge so that we can respond to requests with business context and company-specific terminology. This “knowledge agent” does the following:
- Generate and store knowledge from past requests to the agents.
- Answer queries so that the knowledge entered by the user can be used for planning.
We combine these processes and tune them to ensure that the user's intended processing is carried out.
Building a collaborative environment between humans and AI through AI-friendly interfaces, not just human-friendly
Although we wrote that the accuracy of code generation by LLM is high, it does not mean that the generated code is correct every time. Therefore, it is necessary to receive and correct errors after execution.
However, the interface that humans usually use is not always the best for AI agents to get information from the code execution. For this reason, the concept of an Agent-Computer Interface (ACI) is also gaining traction. It means an interface design that allows the AI agents to easily obtain information from the code execution, such as other existing data processing, as feedback, as well as error handling.
This is easy to imagine since HCI (Human-Computer Interface) is a discipline that studies how humans and computers interact.
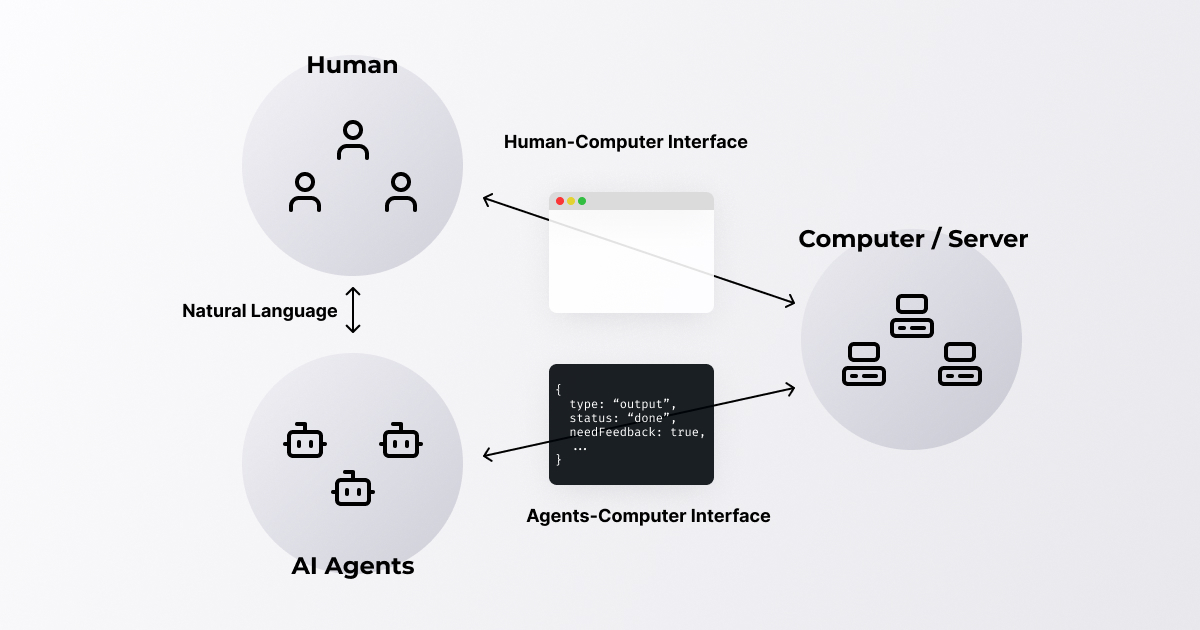
At Morph, we are building a workspace that uses both humans and AI agents as low-code tools, so we need to be aware of both. The workspace should be optimized for the AI agent as well, rather than AI agent unilaterally adapting to the human execution environment.
To realize a future where everyone can utilize data assistants

AI agents are evolving by solving challenges every day.
We believe that there will be a future where everyone can hire an AI data assistant and can focus on their business and performance improvement. Our approach is selecting the appropriate models for each agent from these LLMs to build the optimal configuration for data processing.
More than the accuracy of code generation, it is important to create an experience where users can make requests as if they were their own colleagues. Therefore, the techniques to build Task Planning and Knowledge agent are crucial.
The development of these functions will require new technological challenges such as Retrieval Augmented Generation (RAG) and other information retrieval and accuracy evaluation technologies.
We are looking forward to the next release of Beta3, which will include a larger update of the inference area.