
Snowflake Summit 2024で発表されたAI機能 (Cortex) を触りながら、活用方法を考える: Biz x Dev ラウンドテーブル


Biz x Dev ラウンドテーブルの連載では、データにまつわるお悩みやトレンドトピックを、エンジニアとビジネス職の対談の形式でお届けします。
本日の参加者
小野寺 隼人 - セールスマネージャー @Morph
Morphのコーポレートセールス担当のマネージャー。
今日は、マーケティングコンテンツのためのデータ活用のお悩みがあるそうです。
柴田 直人 - CEO/バックエンドエンジニア @Morph
当社CEOですが、Morphではリードバックエンドエンジニアも兼任。
動画
Snowflake Summit 2024が開催されましたね!
小野寺:
先日Snowflake Summitが開催されまして、その中でもやはりAI系の発表が多くありました。
今日は、SnowflakeのCortexを実際の業務に活用するには、というテーマでディスカッションできればと思います。
Snowflake Summit 2024の発表で、注目しているものはありますか?
柴田:
まずはダークモードが嬉しかったですね。
あとはやはり、AIに関連する発表が多くて、「AI Data Cloud」というコンセプトも強く押し出していましたね。
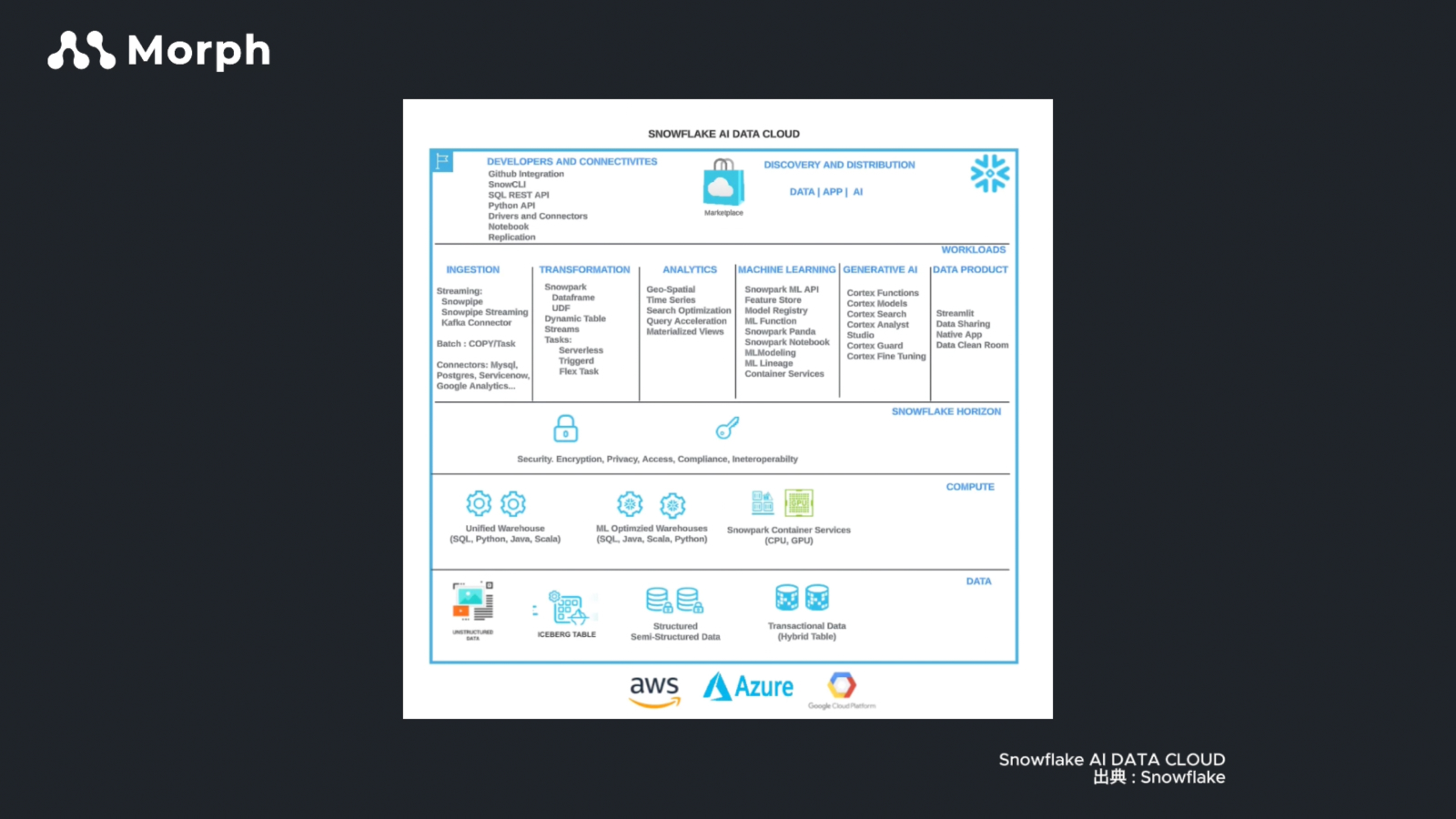
小野寺:
私もNotebookは触ったことがあったので発表内容もわかりやすかったのですが、「こんなこともできるようになったんだ」と感じるものが多かったです。
柴田:
ローカルに環境構築しなくてもAI機能を使えるようになるっていうのがいいですよね。Snowflake上で色々なことができてしまいますね。
Notebook関係でいうと、Streamlitのコマンドも実行できるので、AI処理から簡単なアプリケーションまで一つのツールでできるのがいいですよね。
小野寺:
そんな発表を見て私も触発されまして、今日はCortexを実際に使いながらディスカッションさせてもらえればと思います。
ECの売上データをLLMを使ってクレンジングしてみる
小野寺:
ECのデータを準備してきました。商品情報をみると、物理的な商品とファンクラブの支払いが混ざっています。
これでは分析上困るので、LLMを使ってカテゴリの分類をやってみました。
これが実際のコードです。
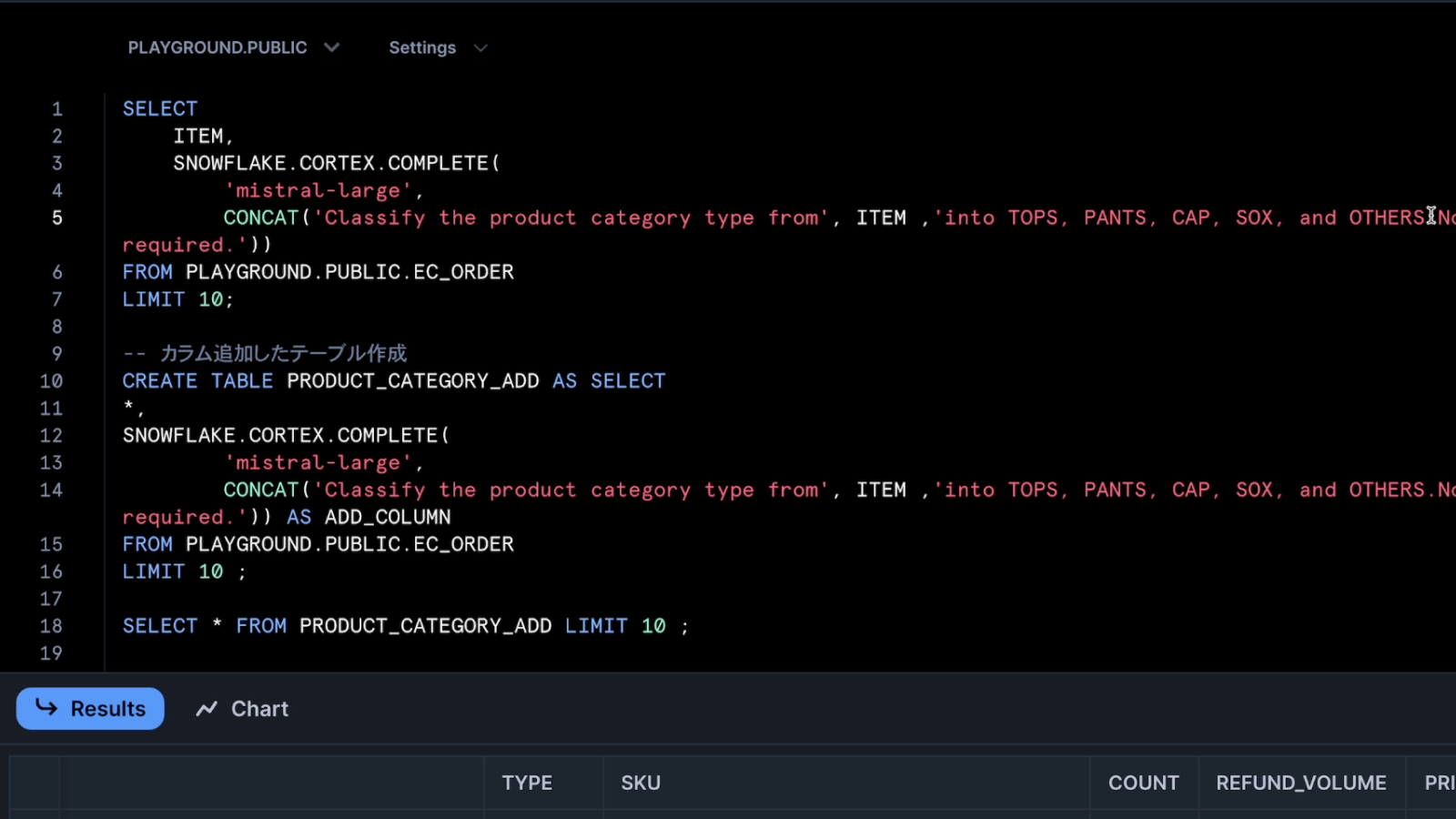
柴田:
SELECT文の中でLLMを呼び出せるんですね。
小野寺:
そうなんです。結果も良好で、実際のお客様のプロジェクトでも使えると思います。
柴田:
今まであれば、SQLでクエリして、PythonからChat GPTのAPIなどを呼び出して処理をした上で、またSnowflakeに戻す必要があったので、だいぶ簡単になりますね。
小野寺:
ビジネス職の自分としても、SQLには慣れているので扱いやすいです。
逆にお聞きしたかったは、こういったツールがあったとしてもPythonを使わないといけないケースってあるのでしょうか?
柴田:
ここまでできれば多くのケースがカバーできてると思います。
一方で、Pythonを使うメリットとしては、最新のモデルがすぐに使えるという点があります。ツールに統合されたソリューションだと、ツール側、つまりはSnowflakeが対応を完了するまで待たないといけませんよね。Pythonを使ってAPIを直接使えば、そこは自由度が上がります。
また、実務上はLLMの処理だけで完結するようなタスクばかりではないと思うので、コードを書くということの強みはまだまだあると思います。
Function Callingのように出力結果のフォーマットを制限するといった、LLMの出力の補完的な命令や処理もあるので、そういったことがどこまでCortexでできるのか気になりますね。
今回のケースですと、ECサイトから出力されたデータだけで試してみてますけど、エクセルなどで保管されてる他のデータと結合してなにかやりたいということもあると思いますね。
小野寺:
そうですね、実際のプロジェクトではPythonの処理も合わせないといけなさそうですね。

Salesforceの見込み顧客のスコアリング
小野寺:
もう一つ持ってきたのが、Salesforceの見込み顧客のデータです。見込み顧客のスコアリングがまだまだ定性的な情報に寄るところが大きいので、もっと定量的にラベル付けしたいと思っています。
定量データを重視した顧客スコアリングの手法はたくさんの情報がありますが、自分が構築できるかというと話は別です。Cortexの機能を使えば簡単にできるのではないか、と思ってやってみました。
私の方でやってみたこととしては、過去に実際に購入してくれた顧客データからモデルを構築して、それを元に見込み顧客のスコアを算出するというものです。
柴田:
これもSQLでできてしまうんですね。
柴田:
少なくともプロトタイプとしては十分ですね。これをベースに実際のデータで試しながら改善していけると思います。
小野寺:
5分くらいで構築できてしまいましたね。
SalesforceとSnowflakeのインテグレーションも強化されましたし、可能性が広がるなと感じましたね。

(https://www.snowflake.com/blog/bi-directional-data-sharing-snowflake-salesforce-ga/ より引用)
柴田:
Zero Copyインテグレーションですよね。めっちゃ楽ですよね。
こういった動きが進んでいくとデータ統合のハードルが下がりますね。次の段階として、ツールを使ったデータ活用に目が向けられていくのではないかと思います。
小野寺:
実際の顧客データって必ずしもCRMだけで管理されてるわけではなくて、オフラインイベントの申し込みデータがスプレッドシートにあったり、問い合わせデータがクラウドに保管されてたりするので、データ統合のハードルが下がることでよりデータドリブンなセールスやマーケティングが実現できると期待しています。
柴田:
たとえば複数プロダクト持っているような企業であれば、アップセルやクロスセルのための包括的なデータ分析が可能になりそうですね。
こういった流れがあると、「良いデータを持っている」ということが競争力になりそうですね。

「良いデータ」を作ることをサポートしたい
小野寺:
そう考えると、Morphでも「良いデータ」を作るということが支援できるといいですよね。
柴田:
そうですね。「良いデータ」を作ることや、LLMを使ったデータ分析ための前処理などをカバーしていきたいなと思いますね。
データ分析において、機械学習だけでなくLLMも使えるとなると、データの前処理に求められることも変わってくるので、Snowflakeのようなツールと補完関係になれると理想的だなと思いますね。