
Morphが取り組む、データ処理特化のAIエージェントの開発: 開発チームからの手紙

以前のブログでは、Morph Beta2にて「ノーコードからローコードへ」アップデートをした裏側を紹介しました。Morph Beta2では同時にAI機能についても大幅なアップデートを行いました。
その中でも目玉機能の一つがAIエージェントです。LLMの発展に伴い注目を集めているAIエージェントですが、今回はMorphが取り組んでいるデータ処理特化のAIエージェントについてお話ししたいと思います。
ローコードへのプロダクトをアップデートした背景については、こちらの記事をご覧ください。
「ノーコードからローコードへ」Beta 2のアップデートについて : 開発チームからの手紙
AIエージェントとは?
Morphで取り組んでいるAIエージェントの話をする前に、まずAIエージェントについて簡単に説明をします。
AIエージェントとは、ユーザーから与えられた目標を達成するためのタスクのプランニングから、データ収集、タスクの実行、更には実行結果の評価を行い、自律的にタスクを実行するソフトウェアプログラムのことを言います。
代表的なAIエージェントには、2023年5月にOSSプロジェクトとして発表されたBabyAGIや、AI software engineerとして注目を集めたDevinなどがあります。
AIエージェントではLLM単体では実行できないような複雑なタスクを処理することができる可能性を秘めています。例えば、以下のような処理を実行させることができます。
- LLMにソースコードを書かせて、そのまま実行をして結果を使って目標を達成する
- LLMがソフトウェアを操作して、複数のソフトウェアに対する入力作業や検索作業を完了する
一方で、エンタープライズの複雑な業務ニーズに応えるためには各AIエージェントが達成すべき目標を定義する必要があります。つまり何でもできるAIエージェントは存在しないため、AIエージェントの専門領域を定義して、最適化をしたUXを構築するということです。
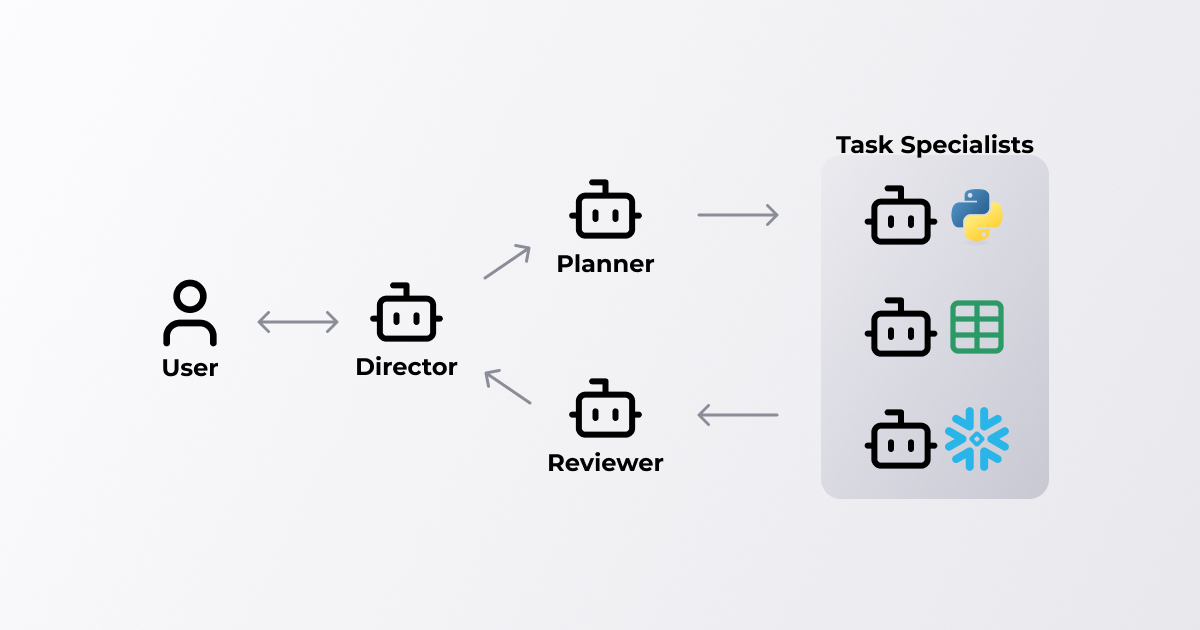
Morphが取り組むデータ処理特化のAIエージェント
Morphでは、LLMのコーディング能力や言語化能力、データ解釈能力を活用してデータ処理に特化をしたAIエージェントを開発しています。Morph上では、SQL, Pythonを実行する環境が整っています。これらのコードをLLMに生成させることによってあらゆるデータ処理にまつわるタスクをこなすことができる状態を目指しています。
下の図に示すように、MorphのAIエージェントでは複数の単一タスクの専門であるエージェントが協力をしてデータ処理を実行する形になっています。これらが連携することでシステム全体では自律的な振る舞いをすることが可能になります。
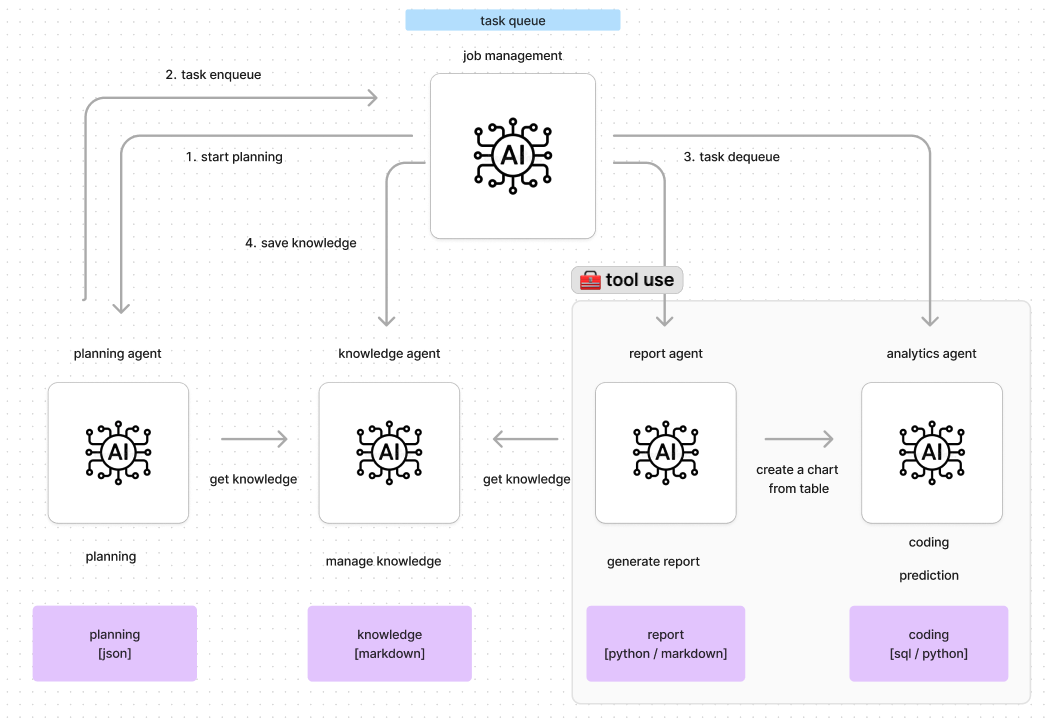
GPTをはじめとして、AIによるコード生成は飛躍的に向上を続けています。そのため、分析対象のデータ構造などが適切に活用できれば、かなり高い確率で正しいコードをAIから直接手に入れることができます。
一方で、AIエージェントの開発を進めていく中で、タスク推論能力が最も重要な役割を果たすことがわかりました。これは、AIエージェントがユーザーから与えられた目標を達成するために必要なタスクの一覧を推論する作業が該当します。
ユーザーは、分析対象のデータに対して所望の分析処理を依頼することができます。この時、AIエージェントは以下のような知識を元に必要なタスク一覧を生成します。
- 利用することができるデータの詳細情報
リクエストされた処理を実行するためのデータが全て利用可能な状況であることを確認します。もし、情報が不足している場合はAIエージェントからユーザーに再度追加の情報を求めます。
- AIエージェントが使用することのできるツールとその説明 [python, sql]
Pythonでは、使用することのできるパッケージやMorph内で用意をしている関数を認識し、タスクの実行のために活用可能なツールを認識します。
また、各種処理の依存関係を管理し分析処理がパイプラインとして実行可能な状態であるようにプランニングをします。
- ユーザーによって入力された事前知識
業界情報や社内特有の用語などで依頼をした場合でも回答ができるように、Knowledgeを管理するエージェントを保有しています。このKnowledge agentは、以下のことを行います。
- 過去の質問やエージェントへの依頼事項から知識を生成して保存する
- ユーザーが入力した知識をプランニングの際に活用できるように、知識の問い合わせに対して回答する。
これらの処理を組み合わせて、ユーザーが意図した処理を確実に実施できるようにチューニングを行っています。
Human friendlyなだけではなく、AIエージェント friendlyなインターフェースを通して人間とAIの協働環境を構築する。
LLMによるコード生成の精度は高いと書きましたが、毎回正しいコードを書くわけではありません。そのため、実行環境から正しくエラーを受け取って修正を行う必要があります。
一方で、人間が普段使用しているインターフェースがAIエージェントが実行環境から情報を取得するために最適だとは限りません。
そのため、ACI(Agent-Computer Interface)という概念も注目されています。
これはエラーハンドリングだけではなく、既存の他のデータ処理など実行環境の情報をAIエージェントがフィードバックとして取得をしやすいインターフェーズデザインのことを指します。
HCI(Human-Computer Interface)が人間とコンピューターの関わり方を研究した学問であることからも、想像がつきやすいと思います。
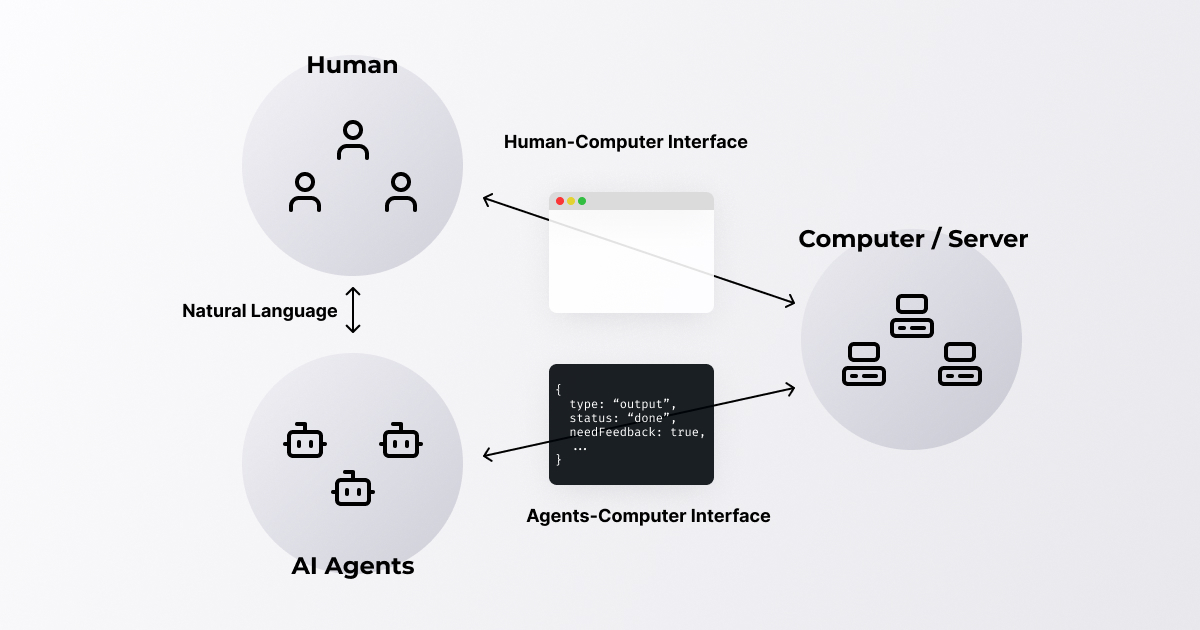
Morphでは、Low-codeツールとして人間もAIエージェントも利用する環境を構築しているので、両者を意識する必要があります。一方でLow-codeツールを開発しているからこそ、AIエージェントが一方的に人間の実行環境に合わせるのではなく、環境自体もAIエージェントに最適化することができます。
誰もがデータアシスタントを活用できる未来を実現するために。

AIエージェントは、新しい課題やテーマを日々解決することで進化しています。
これらの課題を乗り越えた先には、誰もがAIデータアシスタントを雇うことができて、コア業務や業績改善に集中ができる未来があると信じています。
LLMはOpenAIやAnthropicをはじめとした汎用的なものから、コード生成のような具体的なタスクに特化したものまで開発が進んでいくと考えられます。私たちは、これらのLLMから各エージェントに適したモデルを選定をすることで、データ処理において最適な構成を構築していきます。
コード生成の精度以上に、「ユーザーが自分の同僚のように依頼ができる」体験を生み出すことが重要です。そのため、タスクプランニングやナレッジを構築する技術が肝になります。
これらの機能開発にはRAGをはじめとする情報検索や精度評価技術など新しい技術的挑戦が必要になってきます。
次回リリースのBeta3では、これらの技術的挑戦を盛り込んだアップデートを予定していますので、公開できるのを楽しみにしています。